Beyond Atlassian Guard: Why Regex Isn't Enough for AI-Era Data Protection
Traditional DLP scans for structured patterns like credit cards. AI-era security needs semantic classification that understands why your strategy docs and compensation plans actually matter.
Beyond Atlassian Guard: Why Regex Isn't Enough for AI-Era Data Protection
Traditional DLP scans for structured patterns like credit cards. AI-era security needs semantic classification that understands why your strategy docs and compensation plans actually matter.
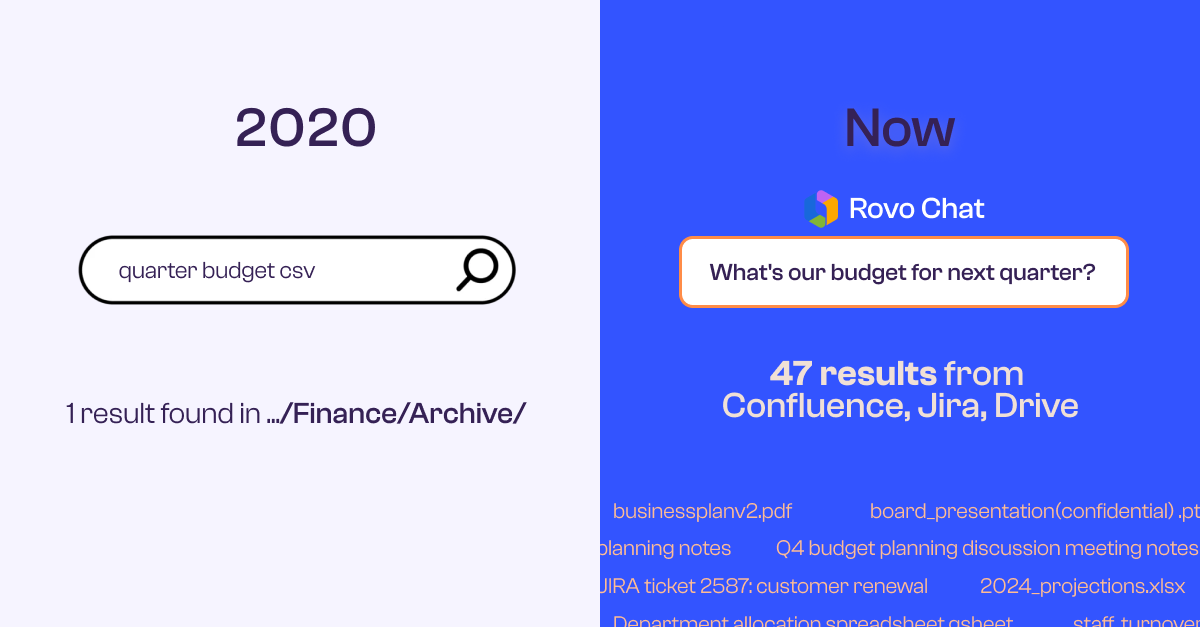
When Atlassian Rovo indexes your Confluence and Jira environments, it surfaces everything you can technically access. And if your data loss prevention relies solely on pattern-matching, you're about to discover just how much sensitive content has been hiding in plain sight.
Atlassian Guard, the platform's built-in DLP tool, uses regex patterns to detect sensitive data. It's looking for things like credit card numbers, social security numbers, and other structured data patterns. But it has no idea whether that spreadsheet titled "Q4_Compensation_Review.xlsx" contains salary data, or whether that Confluence page discussing your product roadmap represents intellectual property worth protecting.
When AI-powered search makes everything discoverable, context-blind detection becomes a liability.
The Fundamental Limitation of Pattern Matching
Traditional DLP tools, including Atlassian Guard, work by scanning content for specific patterns—regular expressions that match known data formats. Need to find credit card numbers? Write a regex that looks for 16-digit sequences. Want to catch social security numbers? Create a pattern for XXX-XX-XXXX.
This approach works reasonably well for structured data types with predictable formats. But here's what it misses:
Historical content that predates your DLP deployment
Guard doesn't retroactively scan your existing Confluence pages or Jira tickets. It only monitors new content going forward. That means years of potentially sensitive data remains unclassified and unprotected, until Rovo makes it searchable.
Unstructured content that matters to your business
A document discussing your M&A strategy doesn't contain SSN patterns or credit card numbers, but it's arguably more sensitive than an old expense report that does. Regex can't tell the difference between a public marketing FAQ and confidential board meeting notes.
Attachments and embedded content
Guard's pattern-matching struggles with complex file types, PDFs, images, and nested documents. If someone uploaded a photo of a whiteboard session where your team mapped out competitive intelligence, regex won't catch it.
Business context that determines actual risk
Even when Guard correctly identifies a data pattern, it operates at the page or file level. It can't tell you that a small snippet of salary information just got pulled into a Rovo response that combined three different Confluence pages. It has no understanding of why specific content is sensitive or what business function it serves.
This is where AI changes the game and exposes the gaps.
When AI Amplifies What Pattern Matching Misses
Rovo doesn't create new security vulnerabilities. What it does is surface existing ones with ruthless efficiency.
Consider a typical scenario: Your finance team created a Confluence space three years ago to collaborate on budget planning. Some pages are restricted, but several were left with default permissions—technically accessible to anyone in the organization, but buried deep enough that nobody would stumble across them through manual navigation.
Atlassian Guard never scanned that historical content. Even if it did, most budget discussions don't contain regex-matchable patterns. They contain prose: "We're planning to reduce headcount by 15% in the EMEA region" or "The board approved a $2M investment in the new product line."
Now someone asks Rovo: "What are our hiring plans for next year?" The AI assistant dutifully searches across all accessible content, finds that buried budget discussion, and helpfully summarizes the headcount reduction - information that was never meant to be company-wide knowledge.
Guard didn't flag anything because there was no pattern to match. The permissions were technically correct, just overly broad. And Rovo followed its mandate: make everything searchable.
This is the AI-era data protection challenge. Your security can't rely on spotting known patterns anymore. You need to understand what your data actually is and why it matters to your business.
The Semantic Classification Advantage
This is exactly why Metomic built semantic labelling—an AI-powered classification engine that understands business context, not just data patterns.
Instead of scanning for credit card numbers and SSNs, semantic classification analyzes file names, content, and metadata to determine what an asset represents in your organization. It recognizes that "Q4_Board_Presentation.pptx" containing financial projections belongs in the "Board & C-Suite" category. It understands that a Notion page discussing compensation structures should be classified as "HR," regardless of whether it contains obvious PII patterns.
Here's how it works differently from regex-based detection:
Multi-layered analysis
Metomic combines traditional pattern matching with machine learning and semantic analysis. We're not replacing regex—we're adding layers of intelligence that understand context. A document might not contain a single regex-matchable pattern but still represent intellectual property, board-level strategy, or HR information that requires protection.
"Even for something as structured as credit card numbers, pure regex creates false positives. We use a layered approach—regex plus contextual analysis—because pattern matching alone misses the nuance. If a 16-digit sequence appears in a product SKU or test data, context tells us it's not actually a payment card. That's why semantic classification isn't just for unstructured data, it's a better approach across the board."
— Morgan Collins, Lead Engineer at Metomic
Business-context classification
Rather than just flagging "sensitive data detected," semantic labelling tells you what kind of sensitive data: Intellectual Property, Board & C-Suite materials, HR documents, Financial records, Customer information, Legal documents, and more. This allows you to prioritize protection efforts based on actual business impact. A leaked marketing brochure poses different risks than leaked board minutes.
Historical and ongoing coverage
Unlike Guard's forward-only approach, Metomic can retroactively scan your entire Atlassian environment, including all those Confluence pages and Jira tickets created before you thought about DLP. We find and classify the sensitive content that's been accumulating for years, before Rovo indexes it.
Cross-platform visibility
When Rovo connects to external apps like SharePoint, Google Drive, or Slack, semantic labelling extends across your entire SaaS ecosystem. You get consistent classification and protection regardless of where data lives. This is crucial for when AI assistants start pulling information from multiple sources into single responses.
Attachment and complex content handling
Our semantic analysis works on complete assets, not just text strings. PDFs, presentations, spreadsheets, even file names and folder structures contribute to classification decisions. That whiteboard photo? If it's in a folder called "Product_Strategy_2025," semantic labelling understands the context.
From Detection to Protection: Making Classification Actionable
Understanding what your data represents is only valuable if you can act on that knowledge. This is where semantic classification transforms your security posture.
In Metomic, you can build DLP policies based on Asset Tags—the semantic classifications we automatically apply. Instead of writing rules that say "block any document containing SSN patterns," you can create policies that say "if an asset tagged as 'Board & C-Suite' is shared publicly, automatically revoke access and notify the security team."
This enables nuanced, context-aware protection that aligns with actual business risk. A document classified as "Marketing" might be fine to share externally. One classified as "Intellectual Property" automatically gets stricter controls. HR documents trigger different workflows than Sales materials.
You can also use semantic labels to prioritize your security team's attention. When Metomic shows you that 47 assets tagged as "Finance" are currently shared with external email addresses, you know exactly where to focus your remediation efforts—no need to manually review thousands of files to determine which ones actually matter.
For organizations preparing to deploy Rovo, semantic classification provides something even more valuable: visibility into what you're about to make searchable.
Before you enable the AI assistant, you can identify and secure your most sensitive content: the board presentations, the compensation spreadsheets, the customer data repositories that have been over-shared for years.
The Reality Check Your Security Posture Needs
Here's what we typically find when we run a Rovo Risk Scan for organizations still relying on pattern-matching DLP:
Hundreds of documents classified as "Board & C-Suite" or "HR" that are technically accessible to broad groups within the organization. These never triggered Guard because they don't contain regex-matchable patterns—just sensitive business information written in plain English.
Financial planning documents, product strategies, and customer information scattered across Confluence spaces with overly permissive settings. Created years ago when the team was smaller and access controls were less formal.
Credentials, API keys, and technical documentation that regex might catch—if they're in the right format and Guard has the right pattern configured. Semantic classification catches them regardless.
Legacy Jira tickets containing sensitive customer support discussions, including PII shared in comments and attachments. Guard never saw them because they predate your DLP deployment.
This isn't a failure of your security team.
It's the natural result of using detection technology designed for a pre-AI era. Pattern matching was sufficient when the risk was someone deliberately searching for specific files. It's not sufficient when AI can synthesize information across dozens of sources in response to casual queries.
Building AI-Ready Data Protection
The arrival of Atlassian Rovo represents a broader shift: AI assistants are becoming standard productivity tools, not experimental features. Microsoft Copilot, Google Duet AI, and Slack's AI features are all following the same pattern. Make everything searchable, summarize across sources, answer questions by pulling from your entire knowledge base.
Your data protection strategy needs to evolve accordingly. That means moving beyond "does this match a known pattern?" to "what does this asset represent, and what level of protection does it require?"
Semantic classification allows you to add the contextual intelligence that AI-era security demands.
You still want to catch credit card numbers and SSNs, pattern matching handles that well. But you also need to identify and protect the strategic documents, the confidential discussions, and the business-critical information that doesn't fit neat regex patterns.
At Metomic, we built semantic labelling specifically to solve this challenge. It works natively across your entire SaaS stack—Microsoft 365, Google Workspace, Slack, Notion, Confluence, and more. It provides the asset-level understanding that enables your DLP policies to protect based on business context, dramatically improving accuracy while reducing false positives.
Because in the AI era, protecting your data isn't just about detecting sensitive patterns. It's about understanding what your assets actually are and why they matter to your business—before someone asks Rovo to summarize them.
Ready to see what Rovo might expose in your Atlassian environment?
Metomic's free Rovo Risk Scan identifies sensitive and over-shared data across Confluence and Jira, showing you exactly what needs protection before you enable AI search. Get in touch to assess your Rovo readiness.

